The history of indexes for the U.S. Federal Census continued with the development of what was called the Soundex system. However, that system requires its own series of articles in other posts. Eventually, all of the paper-based indexing systems were replaced by the internet and online programs that either reproduced the paper indexes or developed systems where manual indexes were supplemented by computer programs that searched every word in the index list.
Due to the fact that until quite recently all of the entries on the census schedules were handwritten producing an index of those entries still requires human manual indexing. Computer programs for reading handwriting are now being developed but the technology is still in its infancy. Fortunately, all of that manual indexing work has now been done and online indexes exist for all of the U.S. Federal Censuses that have been released to date through 1940.
Searching online especially of indexes requires a certain amount of experience and strategy. Over time, you'll begin to realize that indexes are not always complete or accurate. The person compiling the index may have misread the handwriting and the information recorded is either inaccurate or incomplete. Despite the existence of a searchable index to the records, manual searching through the census schedules may be necessary if the indexing was incomplete or inaccurate. In this case, a search can be made of a small geographic area such as a town or village fairly quickly by looking at the digital copies of the census schedules for that location. It is also a good idea to search for all possible variations of the names being searched. There is always the remote possibility that the particular person you're searching for was missed by the enumerators for the US Federal Census but this is quite uncommon and usually the reason that a person or family is missing is due to the fact that the person or family moved. The combination of misread records and people who moved makes searching census records a learned skill rather than following a straightforward set of instructions.
As mentioned previously, there are various fully indexed copies of the entire US Federal Census records available on several websites. In addition, partial copies of the censuses are available on additional websites. Some of these are also indexed. Each website will have its particular way of storing and searching its own census records. Successful searching on any particular website usually requires some instruction or experimentation with using the particular website in question. The following is an overview of how to access the various indexes available online.
FamilySearch.org
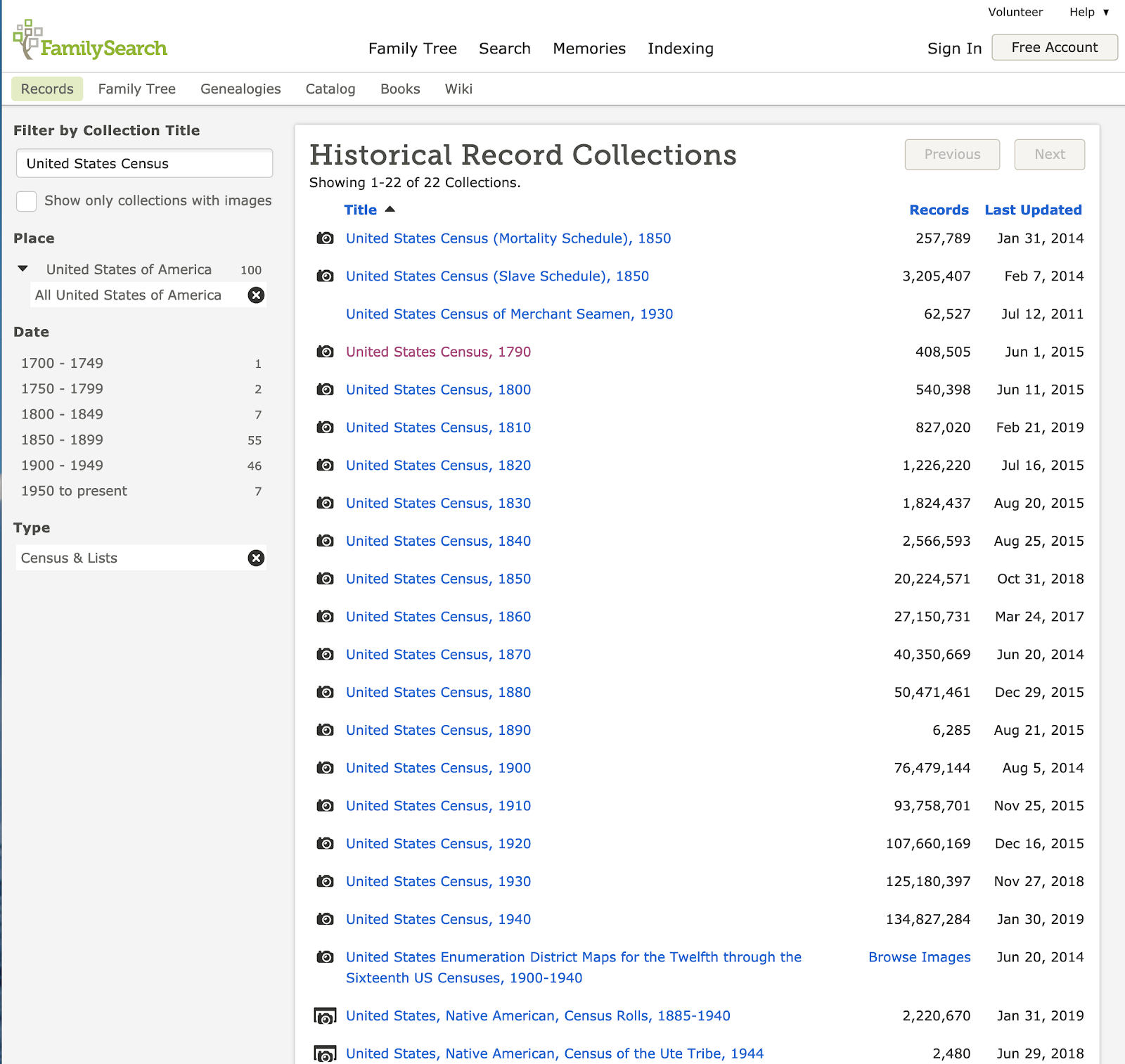
FamilySearch.org is a free website and has a complete set of the US Federal Census records from 1790 to 1940. The records are completely searchable.
FamilySearch.org does require a free registration. You can search all of the records on the website which will include a search of the census records if applicable or you can search each of the census years individually. Here is a search screen for searching the 1880 US Census:
Of course, you always have the option of browsing through millions of images looking for your ancestors.
Ancestry.com
Ancestry.com is a subscription website however free access to the program is available in FamilySearch Family History Centers around the world. There are 5000+ search Family History Centers available for free public use. For the location of the nearest Family History Center go to the Help section of
FamilySearch.org. The free Family History Center version of the website does not allow you to develop or maintain a personal family tree.
As with
FamilySearch.org,
Ancestry.com also provides a way to search individual censuses or do a global search which will include all of the census records. Here is a screenshot of part of the website's search form for the 1880 US Federal Census.
With so many options for searching, the most efficient strategy mandates that you begin your searches with a minimal amount of information and keep adding information until you begin to see usable results from your searches. Of course, this method of searching implies that you know more than a name or a name and the date. Since census records are geographically compiled knowing the location where your ancestors lived is close to absolutely necessary in order to identify the right person or family.
Findmypast.com
Findmypast.com is primarily a website with records from the British Isles and the former British Empire however during the past few years the website has been accumulating millions of records from the United States (technically a former colony of Great Britain). Subsequently, the website has a very useful and complete collection of the US Federal Census as well as many state censuses from around the United States.
Findmypast.com is also a subscription website. Many genealogists hesitate to subscribe to more than one large online website, however, even though the records would seem to be cumulative in the case of US censuses the other records on the website certainly merit the price of the subscription. Here is a screenshot of the website's form for searching the 1880 US Census:
As mentioned previously, knowing the general location is helpful in any genealogical search but in many cases, accurate information can only be obtained by knowing the exact location where the ancestors lived.
Findmypast.com is also available for free at FamilySearch Family History Centers around the world. Again, the free Family History Center version of the website does not allow you to develop or maintain a personal family tree.
MyHeritage.com
MyHeritage.com has a technologically advanced search capability called SuperSearch™. Although it is possible to do a manual search on this website,
MyHeritage.com works best when the user allows the website's SuperSearch™ technology to search for records in a family tree maintained by the user. With a family tree, the program will provide links to all of the census records available. However, if you choose to do a manual search there are search forms available.
MyHeritage.com is also a subscription website and searching requires a membership. However, it is also available for free at FamilySearch Family History Centers around the world, of course, with the limitation that the free Family History Center version of the website does not allow you to develop or maintain a personal family tree.
MyHeritage.com also has an extensive set of US state census records that are completely searchable.
Each of these four websites has an index list of the census collections available. On
FamilySearch.org, the list of available collections is contained in the Historical Record Collections. There is an option to view all collections and search for individual categories of record collections. On the
Ancestry.com website, there is a link under the search menu for the Card Catalog which contains filters that allow you to view different sets of collections including census records. On the
Findmypast.com website, there is a provision under the search menu item to view the A-to-Z of record sets which can also be filtered to show census records. On the
MyHeritage.com website, There is presently a Research tab at the top of the startup page that contains a link to search all recordsAnd there is a way to filter the list to search for census records.
There are a lot more census records online so stay tuned for the next part of this particular series.
Here are links to the previous posts in this series:
Part Four:
https://genealogysstar.blogspot.com/2019/02/step-by-step-guide-to-using-online_23.html